
前回述べた通り、マルコフ連鎖による文章作成のコードを書いてみた。辞書ファイルの保存を言語に関係無く容易に出来る様にするため、統計分析で用いることの多い二次元配列にした。
辞書のサイズが今後増えることを考えればツリー構造にすべきだろうけど、取り敢えず今は単純な2次元配列。
もう出し尽くされた感のあるテーマだけどコードは下の通り。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 |
def paragraphSplit(text, words) temp = "" input = "" open(text) do |f| f.each do |line| temp << line end end input << temp sentence = input.scan(/[^.?]*./) sentence.each do |s| fragments = s.split count = 0 fragments.each do |word| if count == 0 then word = "%START%" + word end words.push(word) count += 1 end end end def writeASentence(markov, newSentence) count = 0 suffix = "" newSentence = "" while count < 100 if newSentence == "" then startCandidates = [] candidatesCount = 0 markov.each do |a, b, c| if a.include?("%START%") then startCandidates << [a, b, c] candidatesCount += 1 end end r = rand(candidatesCount) a = startCandidates[r][0] b = startCandidates[r][1] c = startCandidates[r][2] newSentence = a + " " + b + " " + c suffix = c count += 1 else rowCount = 0 candidates = [] markov.each do |a, b, c| if suffix == a then; candidates << [a, b, c] rowCount += 1 end end r = rand(rowCount) b = candidates[r][1] c = candidates[r][2] newSentence += " " + b + " " + c suffix = c count += 1 end if suffix.include?("%END%") then newSentence.gsub!("%START%", "") newSentence.gsub!("%END%", "") return newSentence break end end end words = [] paragraphSplit('./NoOyesRulfo.txt', words) markov = [] unless words.size < 3 for i in 0..words.size - 2 do next if words[i].include?(".") or words[i].include?("?") if words[i+2] == nil or words[i+1].include?(".") or words[i+1].include?("?") then markov << [words[i], words[i+1], "%END%"] elsif words[i+2].include?(".") or words[i+2].include?("?") then markov << [words[i], words[i+1], words[i+2] + "%END%"] else markov << [words[i], words[i+1], words[i+2]] end end end puts "-----let's generate sentences-----" count = 1 while count <=10 do sentence = writeASentence(markov, sentence) puts ("No. " + count.to_s + ": ") puts sentence puts"" count += 1 end |
物凄く単純。これはキチェ語に限らず単語間を空白で話す言語であれば何語にも使える。例としてJuan RulfoのNo oyes ladrar a los perrosを辞書に取り入れてみた。出力結果はこんな感じ。
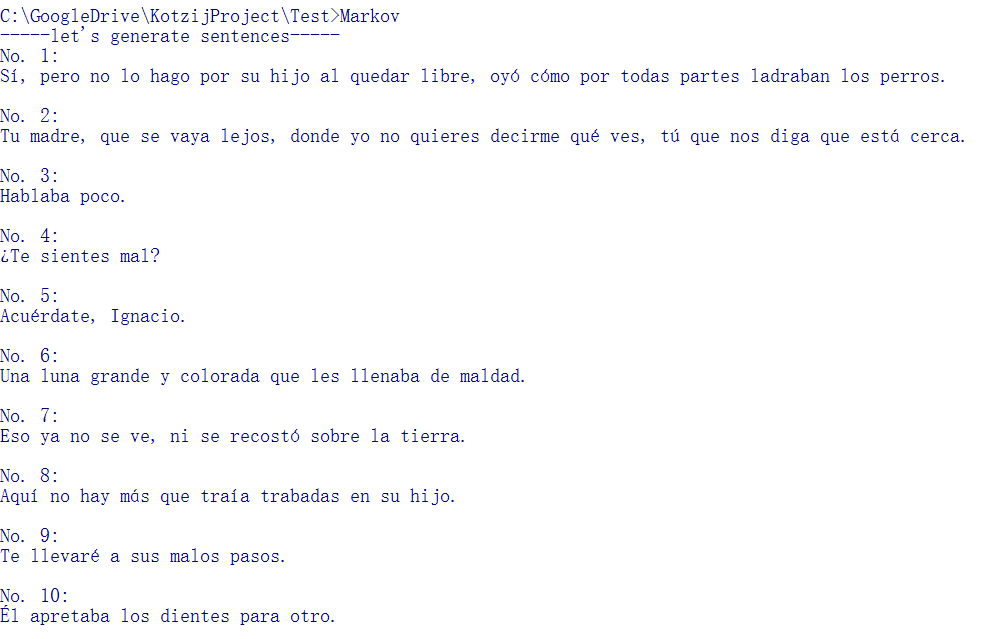
英語で書かれた「老人と海」を採り入れた場合の出力例。

英語とスペイン語で色んな文章を採り入れて試した結果、ある程度しっかりとしたボット・プログラム、つまり回答をマルコフ連鎖は使い物にならないということ。ベースとしてはマルコフ連鎖は使えるけどある程度文法を考慮した仕様にしたり、キーワードで返答を作成するのであれば、文章の構築方法も頭から書き始める以外の選択肢も必要。それが分かっただけでも収穫かな。
取り敢えず、このコードをTzijonikに取り入れてから改良していこうと思う。



























