Javaに移植したTzijonikプログラムを基にJARファイルを作ってみた。
辞書や単語リストの面ではまだまだだけど、恐らく世界初のマヤ・キチェ語のChatbot、つまり人口無脳プログラムではないかなと思う。ダウンロードはココから。
辞書ファイル等を改善しつつ、アンドロイド・アプリとしての開発を始めようと思う。

Javaに移植したTzijonikプログラムを基にJARファイルを作ってみた。
辞書や単語リストの面ではまだまだだけど、恐らく世界初のマヤ・キチェ語のChatbot、つまり人口無脳プログラムではないかなと思う。ダウンロードはココから。
辞書ファイル等を改善しつつ、アンドロイド・アプリとしての開発を始めようと思う。
LaTeXでスペイン語の文章を書く時はこれまでinputencパッケージを使って、アクセント文字とかを使ってきたけど、最近、出先ではSharaLaTexを使うことも多く、そうすると.texファイルを読み込む際に文字化けしてしまう。
そうするとパッケージでは対処できないのでアクセントも記号(\’aとか)を用いることとした。
でスペイン語で使う逆さまのクエスチョンマークだけどこれは
|
1 |
\textquestiondown |
と書くそう。
10年以上LaTeXを使ってきて初めて知った。。。
TzijonikプログラムをJavaに移植中。
で、JPanelを用いてGUIで作っているけど、ユーザーの入力欄に「ここにメッセージを入力する」ということを伝えるためにヒント(hint/prompt text)を表示したいを思った。
ヒント情報はテキストを入力する際には消えてくれないとヒントそのものも入力されてしまうので、そういう仕様のものを探してみた。色々探したけど、中々思った様なものが無かったので結局自分で書くことに。備忘録として残しておく。
まぁ、そんな大したものではないけど。
ポイントとしてはActionListenerインターフェイスを継承することと、addFocusListenerをオーバーライドするだけ。オーバーライドで好む仕様に変えればいい。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
inputField = new JTextField(""); inputField.setFont(new Font("Courier New", Font.PLAIN, 24)); //font if(inputField.getText().length()==0){ inputField.setText("Tz'ij"); inputField.setForeground(Color.BLUE); } inputField.addFocusListener(new FocusListener(){ @Override public void focusGained(FocusEvent e){ putField.setText(""); inputField.setForeground(Color.BLACK); } @Override public void focusLost(FocusEvent e){ if(inputField.getText().length()==0){ inputField.setText("Tz'ij"); inputField.setForeground(Color.BLUE); } } }); |
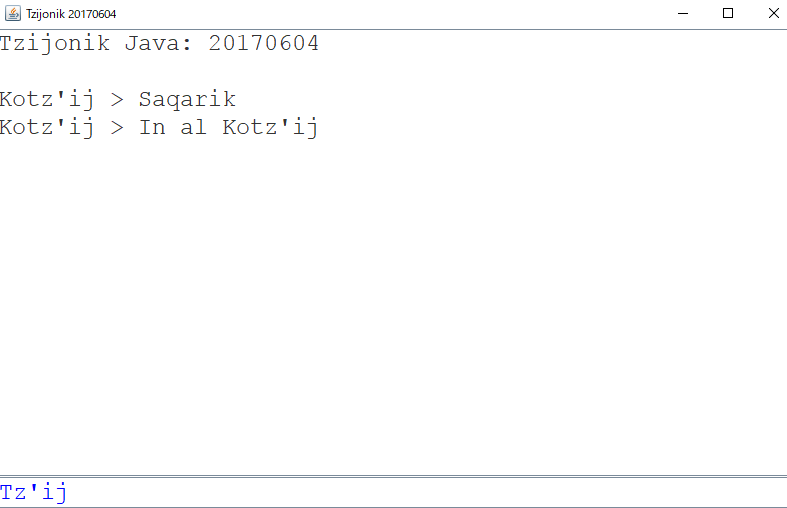
こんな風に出力される。ヒント情報は実際には灰色で表示させているけど、ここでは分かりやすく青で。最初はこう表示されているけど、入力しよう(つまりフォーカスされると)とすると
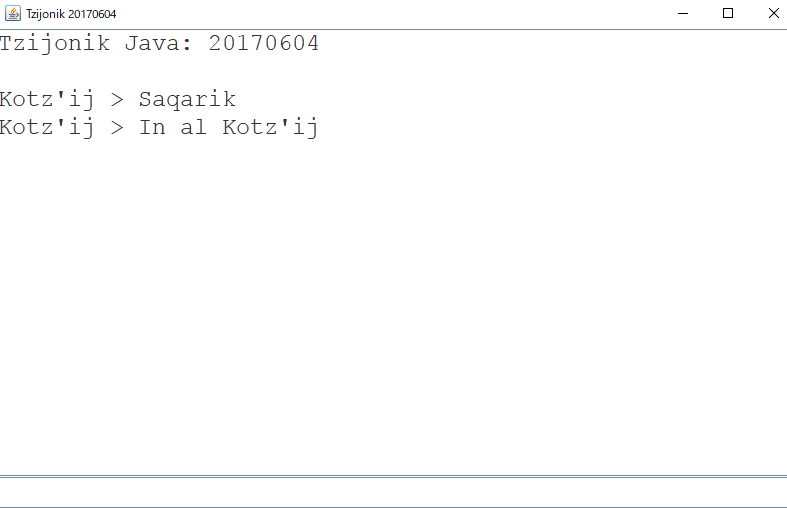
ヒント情報が消えてなくなる。

入力したテキストはヒント情報の色(今回の例では青)ではなく、黒で表示される。
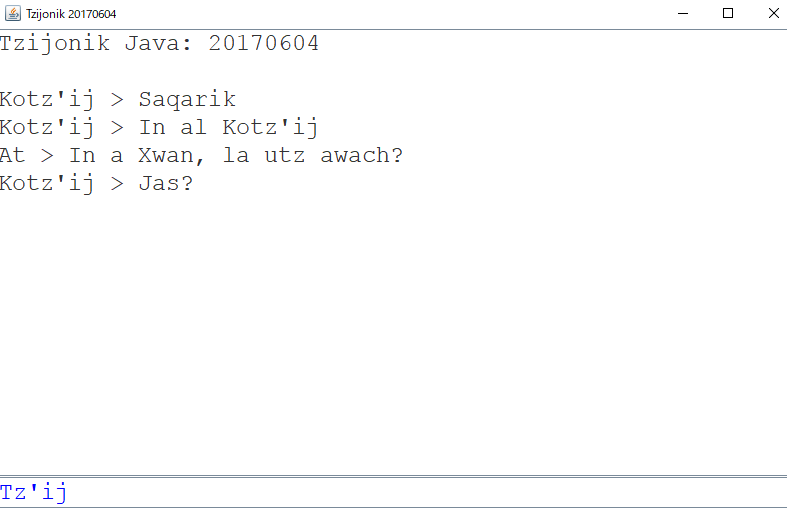
入力欄からフォーカスが外れ、且つ入力欄に何も入力されていなければ再度ヒントが表示される。
ちなみに「tz’ij」とはマヤ・キチェ語で言葉とか単語という意味。つまり英語で言う「word」をここに入力してというヒント。
ここ数日間取り組んできたマルコフ連鎖による文書生成アルゴリズムをようやくTzijonikプログラムに取り入れた。重要な更新なのでバージョンを2にした。 慣れないRubyで色々とメソッドを書いたので、ttr_readerとか今まで曖昧だった部分も理解できる様になった。
コードはやはりDictionary.rbとResponder.rbへの追加修正が主。Dictionary.rbにはマルコフ連鎖関連の下記コードを追加:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
def studyMarkov(input) words = [] fragments = input.split count = 0 fragments.each do |word| if count == 0 then word = "%START%" + word end words.push(word) count += 1 end unless words.size < 3 for i in 0..words.size - 2 do next if words[i].include?(".") or words[i].include?("?") if words[i+2] == nil or words[i+1].include?(".") or words[i+1].include?("?") then @markov << [words[i], words[i+1], "%END%"] elsif words[i+2].include?(".") or words[i+2].include?("?") then @markov << [words[i], words[i+1], words[i+2] + "%END%"] else @markov << [words[i], words[i+1], words[i+2]] end end end end def saveMarkov open('dictionaries/MarkovDic.txt', 'w') do |f| markov.each do |a, b, c| f.puts([a + " " + b + " " + c]) end end end |
それからResponder.rbにはマルコフ連鎖で回答を作成するクラスを追加:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
class MarkovResponder < Responder def response(input, mood) count = 0 suffix = "" newSentence = "" while count < 100 if newSentence == "" then startCandidates = [] candidatesCount = 0 @dictionary.markov.each do |a, b, c| if a.include?("%START%") then startCandidates << [a, b, c] candidatesCount += 1 end end r = rand(candidatesCount) a = startCandidates[r][0] b = startCandidates[r][1] c = startCandidates[r][2] newSentence = a + " " + b + " " + c suffix = c count += 1 else rowCount = 0 candidates = [] @dictionary.markov.each do |a, b, c| if suffix == a then; candidates << [a, b, c] rowCount += 1 end end r = rand(rowCount) b = candidates[r][1] c = candidates[r][2] newSentence += " " + b + " " + c suffix = c count += 1 end if suffix.include?("%END%") then newSentence.gsub!("%START%", "") newSentence.gsub!("%END%", "") return newSentence break end end end end |
プログラムを起動してみる。

5割の確率でマルコフ連鎖で生成された文章で返事をするようにしている。ただ、入力した文章からキーワードを拾っている訳ではないので、意味のある会話にはなりにくい。でもKotzi’ijがある程度長い返答を出来るようにはなった。
今後はキーワードを拾う仕様にすることと、文法を考慮した上でマルコフ連鎖アルゴリズムに修正を加える必要がある。ただ、そうするとマルコフ連鎖では無くなってしまうけど。
昨日載せたコードを少し修正してみた。辞書ファイルへの書き込みも加えた。
MarkovChain.rb
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
def paragraphSplit(text) words = [] temp = "" input = "" open(text) do |f| f.each do |line| temp << line end end input << temp sentence = input.scan(/[^.?!]*./) sentence.each do |s| fragments = s.split count = 0 fragments.each do |word| if count == 0 then word = "%START%" + word end words.push(word) count += 1 end end return words end def writeASentence(markov) count = 0 suffix = "" newSentence = "" while count < 100 if newSentence == "" then startCandidates = [] candidatesCount = 0 markov.each do |a, b, c| if a.include?("%START%") then startCandidates << [a, b, c] candidatesCount += 1 end end r = rand(candidatesCount) a = startCandidates[r][0] b = startCandidates[r][1] c = startCandidates[r][2] newSentence = a + " " + b + " " + c suffix = c count += 1 else rowCount = 0 candidates = [] markov.each do |a, b, c| if suffix == a then; candidates << [a, b, c] rowCount += 1 end end r = rand(rowCount) b = candidates[r][1] c = candidates[r][2] newSentence += " " + b + " " + c suffix = c count += 1 end if suffix.include?("%END%") then newSentence.gsub!("%START%", "") newSentence.gsub!("%END%", "") return newSentence break end end end def markovDic(words) unless words.size < 3 markov = [] for i in 0..words.size - 2 do next if words[i].include?(".") or words[i].include?("?") if words[i+2] == nil or words[i+1].include?(".") or words[i+1].include?("?") then markov << [words[i], words[i+1], "%END%"] elsif words[i+2].include?(".") or words[i+2].include?("?") then markov << [words[i], words[i+1], words[i+2] + "%END%"] else markov << [words[i], words[i+1], words[i+2]] end end end return markov end |
MarkovChainTestKiche.rb
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
require '.\MarkovChain' words = [] markov = [] words = paragraphSplit('./MINEDUC.txt') markov = markovDic(words) count = 1 while count <=10 do sentence = writeASentence(markov) puts ("Sentence " + count.to_s + ": ") puts sentence puts"" count += 1 end open('./MarkovDic.txt', 'w') do |f| markov.each do |a, b, c| f.puts([a + " " + b + " " + c]) end end |
辞書ファイルの読み込みはこの様に:
|
1 2 3 4 5 6 7 |
markov = [] open('./MarkovDic.txt') do |f| f.each do |line| a, b, c = line.split markov << [a, b, c] end end |
単純だけど必要なことは全てこれらのコードで出来ている。しかし、コードを見ると統計分析を行っているような書き方になっている。癖が抜けないなぁと思う。



























